I ran into an interesting quirk while parsing some text today. Before I dive in, let’s establish some background. I’m parsing some comma-delimited data from a text file that looks like this:
0x5d,3,0x10060,(0x00800513),x10,0x8
0x2d41854,3,0x80001a14,(0xbffd)
0x2d41855,3,0x80001a12,(0x0001)
0x2d41856,3,0x80001a14,(0xbffd)
0x2d41857,3,0x80001a12,(0x0001)
It has variable width hex values where each line has at least three fields, but some have more. I only really care about the first and third fields. In my mind, I broke down the parsing into three pieces:
- For each line in the file…
- split the line on the commas into a list, then…
- select the first and third elements, and convert them into integers
It seemed simple enough that I could make my pandas DataFrame in a line or two.
Here’s some simplified code that I produced:
import pandas as pd
def load_file_as_df(filename: str) -> pd.DataFrame:
with open(filename) as fp:
return pd.DataFrame.from_records(
(
(int(tsc, 16), int(pc, 16))
for line in fp
for tsc, _, pc, *_ in line.strip().split(",")
),
columns=["Timestamp", "PC"]
)
Can you spot the bug? Neither could I. I’ll explain the code I wrote piece-by-piece, and then go into why I was wrong.
Explaining my Code
CSV files are lists of lists
I simple view of CSV data is to look at it like lists of lists. So that meant looking at elements in a nested list. My go-to pattern for looking at a flattened-view of nested lists comes from this StackOverflow post. With the main idea reproduced here for posterity
nested_lists = [[1,2,3],[4,5,6],[7,8,9]]
flattened_list = [element for sublist in nested_lists for element in sublist]
As someone who came to Python after being exposed to C and C++, learning about nested comprehensions really gave me the feeling that Python is just machine-interpretable pseudocode, for better or worse. The nested list comprehension that generates the following bytecode:
2 0 RESUME 0
2 BUILD_LIST 0
4 LOAD_FAST 0 (.0)
>> 6 FOR_ITER 9 (to 26)
8 STORE_FAST 1 (sublist)
10 LOAD_FAST 1 (sublist)
12 GET_ITER
>> 14 FOR_ITER 4 (to 24)
16 STORE_FAST 2 (element)
18 LOAD_FAST 2 (element)
20 LIST_APPEND 3
22 JUMP_BACKWARD 5 (to 14)
>> 24 JUMP_BACKWARD 10 (to 6)
>> 26 RETURN_VALUE
Then we extend the idea by combining with some extended iterable unpacking and you get the following snippet from above:
pd.DataFrame.from_records(
(
(int(tsc, 16), int(pc, 16))
for line in fp
for tsc, _, pc, *_ in line.strip().split(",")
),
columns=["Timestamp", "PC"]
)
The Mistake
It turns out, the python interpreter can’t quite combine iterable
decomposition and comprehensions the way that I thought, you have
to wrap the .split(",") call in what looks like another list:
pd.DataFrame.from_records(
(
(int(tsc, 16), int(pc, 16))
for line in fp
for tsc, _, pc, *_ in [line.strip().split(",")]
), # this guy⤴ and this guy⤴
columns=["Timestamp", "PC"]
)
This broke my brain a little bit, because the .split(",") is already a list.
Doesn’t wrapping it in the square list mean it’s now a double-nested list? I didn’t
understand. I went to Compiler Explorer looking for answers.
Here’s the diff of the bytecode for the correct generator expression and the
the one I wrote:
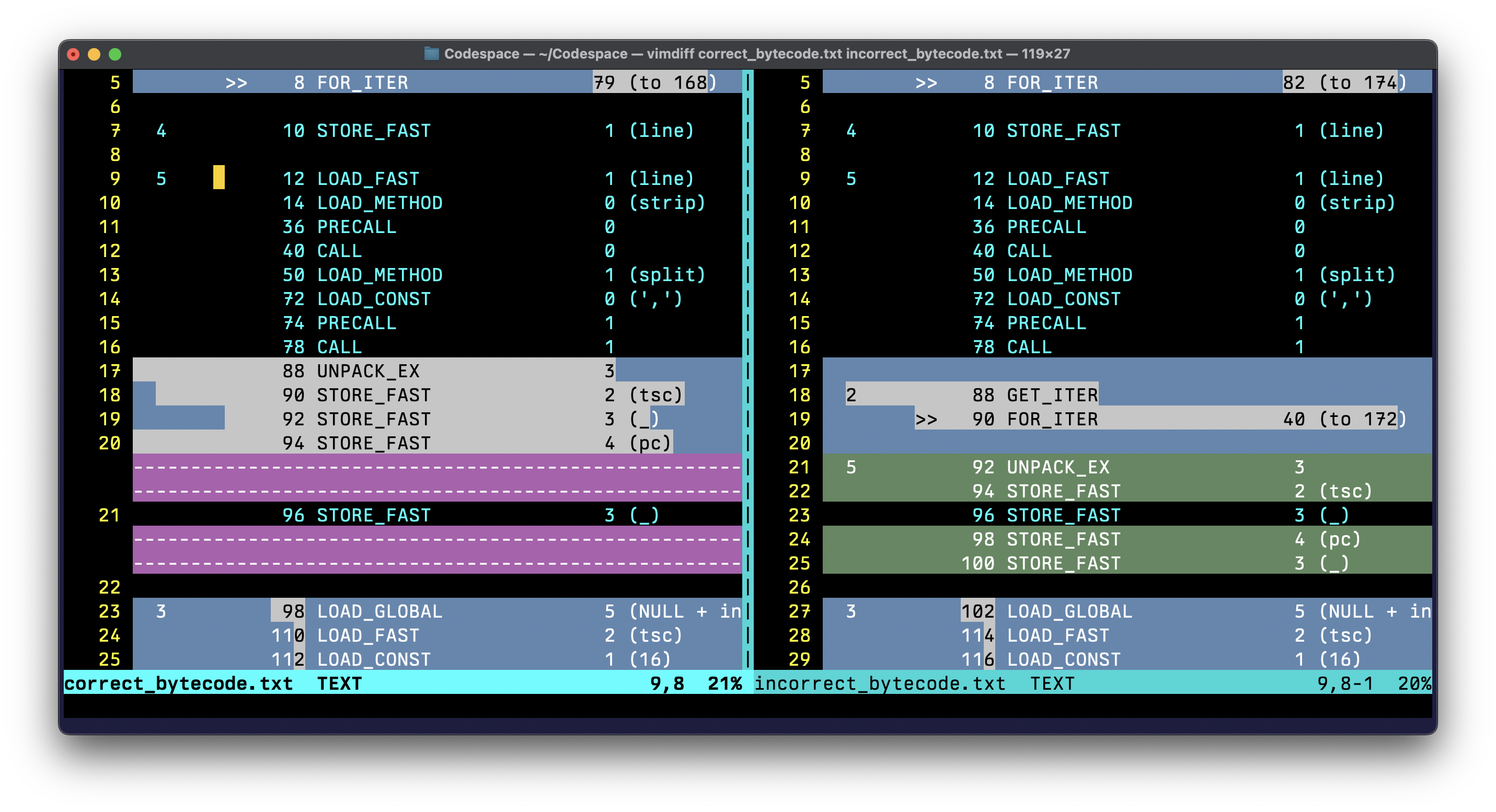
Not the most intuitive, but we have a better picture of what’s going on here. Can you
see it yet? The problem in the old code is that it silently converted the.split()
to an iterator BEFORE unpacking. I’m not certain, but I believe this is inherently
tied to implementation details established when the PEP for list comprehensions was
originally proposed.
I actually figured this out with the help of CPython contributor Crowthebird demonstrated the problem with the code rewritten without using comprehensions.
The incorrect approach does this:
splitted = ["0x2d41854", "3", "0x80001a14", "(0xbffd)"]
for tsc, _, pc, *_ in iter(splitted):
data.append((int(tsc, 16), int(pc, 16)))
The correct approach does this:
tsc, _, pc, *_ = splitted
data.append((int(tsc, 16), int(pc, 16)))
Could this be something that you fix?
This is a fault in my understanding of the Python interperter, not a fault with the interpreter itself. I don’t think changing the language to fit my intuitive syntax would be for the better because it makes it difficult to differentiate when the container should be unpacked and re-used in the nested case, versus the erroneous formation of a list comprehension returning tuples, mentioned by Guido as the disallowed syntax in PEP 202.